How to Supercharge Your Django App: A Guide to Unleashing Peak Performance Through Database Indexing
Summary of the second chapter of the book "The Temple of Django Database Performance" Part I.


The writer of the book "The Temple of Django Database Performance" made a bold claim in its preface.
Most performance problems in web applications come down to one thing: the database
I think I have to agree with this as Django itself as a framework is excellent and it provides us with the tools that can get us started but its ORM is quite stressful to master as its API keeps evolving and its query plans are not always the best for every situation! So it all comes down to the database performance and how to master it.
In this book summary series we emphasize the importance of going beyond Django's API documentation to truly master database performance. We will highlight the need to become experts at this and outline a certain tool set, including using profiling tools, understanding database query plans, identifying the right index for optimization, and employing advanced techniques like server-side cursors and key set pagination for efficient data processing.
What is an Index?
Best way to define it is that it's similar to a Book Index, without updating the book constantly like in databases.
In the same way we use a book's index to quickly find information without reading the entire book, a database index serves a similar purpose. It is smaller than the complete dataset, allowing for faster search operations. The index copies relevant information into a separate location and associates specific terms, or strings if you will, with specific locations in the database (analogous to chapters in a book).
Although, unlike book indexes, database indexes face the challenge of constant updates as database content changes frequently. Databases need to automatically and regularly update their indexes. Without indexes, searching through all the data in a database becomes slow and inefficient, especially for large tables, making the database practically unusable for certain operations.
What is an Index in the technical sense?
In technical terms, a database index is a data structure that improves the speed of data retrieval operations on a database table. It works by providing a quick and efficient way to locate rows in a table based on the values in one or more columns.
Here's a breakdown of key aspects:
- Structure: A database index is typically implemented as a data structure like a B-tree or hash table, associating key values with the physical location of corresponding data in the table.
- Columns: Indexes are created on specific columns of a table. These columns are chosen based on the queries that are frequently performed, aiming to accelerate the retrieval of data.
- Sorting and Searching: The index organizes the values in a sorted order, which enables faster search operations. Instead of scanning the entire table, the database engine can use the index to locate the specific rows that satisfy a given condition.
- Performance: Indexes significantly improve the performance of SELECT queries but can potentially slow down data modification operations (INSERT, UPDATE, DELETE) because the index also needs to be updated.
- Uniqueness: Indexes can enforce uniqueness constraints, ensuring that the values in the indexed columns are unique across the table.
In essence, a database index is a tool for optimizing the retrieval of data from a database table, providing a balance between query performance and the overhead of maintaining the index itself.
In today's relational databases, the default and prevalent type of index is the B-tree. While there are alternative types, the B-tree index is foundational and widely used.
The B-tree Index
A B-tree database index is a data structure commonly used to organize and store keys in a database in a sorted order. The "B" in B-tree stands for "balanced," indicating that the tree maintains a balanced structure, ensuring efficient search, insertion, and deletion operations.
A B-tree index speeds up searching by maintaining a tree whose leaf nodes are pointers to the disk locations of table records and it is particularly well-suited for databases because it keeps the height of the tree balanced, resulting in consistent and logarithmic time complexity for various operations.
It's also a self-balancing tree, meaning that as data is added or removed, the tree automatically adjusts to maintain its balanced structure, optimizing query performance in databases.
The Significance of Page Size in Databases
The DB page size refers to the fundamental unit of data storage and retrieval that is used for index and table storage within a database. It represents the amount of data that can be read from or written to disk in a single I/O operation. It is a configurable parameter set at the time of database creation and can vary among different database management systems.
PostgreSQL and MySQL store data in files on disk, with PostgreSQL using an 8 KB default page size, and MySQL's InnoDB storage engine using a default page size of 16KB. SQLite, on the other hand, stores the entire database as a single file, and in both cases, data within these files is typically organized into units called "Pages."
The size of database page is significant because, in theory, larger page sizes allow more rows to fit in a single page. This means fewer pages need to be fetched from disk to fulfill a query, potentially improving performance. However, the actual impact depends on factors like the storage medium (SSD, HDD) and the specific application. It's better to profile and assess performance when adjusting the page size.
How to Create an Index?
Now that we’ve defined indexes and established that the indexes you are most likely to use and create yourself are B-trees, it is time to introduce indexing in practice!
Create an Index in SQL
An index is made from the content of a set of columns. That might be one column, or several like this:
CREATE INDEX my_index_name ON name_of_my_table(name_of_my_column);
-- OR on multiple columns as such
CREATE INDEX my_index_name ON name_of_my_table(
name_of_my_column, name_of_my_other_column
);After creating the index, the database will keep it updated automatically. This happens every time you write data and is quite crucial for the performance of our DB.
Please note that Indexes can include a WHERE clause, determining the portion of a column's data that is indexed. This feature is known as a Partial indexing or "Partial Index", and it will be discussed in another blog article.
Create an Index through Django Model in Development mode
With its models and migrations system, Django Framework has the capability to generate indexes for us. If you've developed a Django app, you likely already have some indexes in place, as Django automatically creates certain indexes for you.
We will pick the Event Model example provided in the original book:
class Event(models.Model):
user = models.ForeignKey(
"auth.User", on_delete=models.CASCADE, related_name="events"
)
name = models.CharField(help_text="The name of the event", max_length=255)
data = JSONField()
class Meta:
indexes = [models.Index(fields=["name"])]
After adding the index in the Meta class of the Event Model, we run the migrations and we should get the addIndex migration as such:
class Migration(migrations.Migration):
dependencies = [
("analytics", "0001_initial"),
]
operations = [
migrations.AddIndex(
model_name="event",
index=models.Index(fields=["name"], name="analytics_e_name_522cb6_idx"),
),
]
which when executed it generates this SQL code:
CREATE INDEX analytics_e_name_522cb6_idx ON analytics_event(name);
This seemed easy enough, it's a different story in production environments though!
Create an Index through Django Model in Production mode
Adding an index to a development database is typically straightforward. However, depending on the database used, the process can be more challenging in a production environment.
In PostgreSQL, the default setting is to lock the table against writes during indexing, potentially causing disruptions in an active system. On the contrary, MySQL with the InnoDB engine does not lock by default.
Databases that lock by default often allow altering this behavior with additional parameters in the CREATE INDEX statement. To implement these parameters in Django, a RunSQL migration is required, where the SQL code needs to be manually written. The following example demonstrates this process with PostgreSQL.
class Migration(migrations.Migration):
atomic = False
dependencies = [
("analytics", "0001_initial"),
]
operations = [
migrations.RunSQL(
"CREATE INDEX CONCURRENTLY"
"analytics_event_name_idx "
"ON analytics_event(name);"
)
]
Please note that PostgreSQL does not allow running a CREATE INDEX CONCURRENTLY operation within a transaction. However, Django executes all migrations within a transaction by default. To work around this limitation and add an index concurrently, you need to set the "atomic" parameter to False, thereby disabling transactions during the process.
Performance difference in READ operations on DB
One of the very first few tools in our arsenal when analyzing the performance of a database is the Query Plan. This is provided by the database engine to tell us how the database intends to execute a query, and often gives us hints about missing indexes.
Imagine we are executing this query:
SELECT "analytics_event"."id",
"analytics_event"."user_id",
"analytics_event"."name",
"analytics_event"."data"
FROM "analytics_event"
WHERE "analytics_event"."name" = 'user.viewed';
With the provided query example, an EXPLAIN query can be executed on the database to obtain additional information about the query plan.
The subsequent example illustrates the result of running an EXPLAIN query using psql, the PostgreSQL command line.
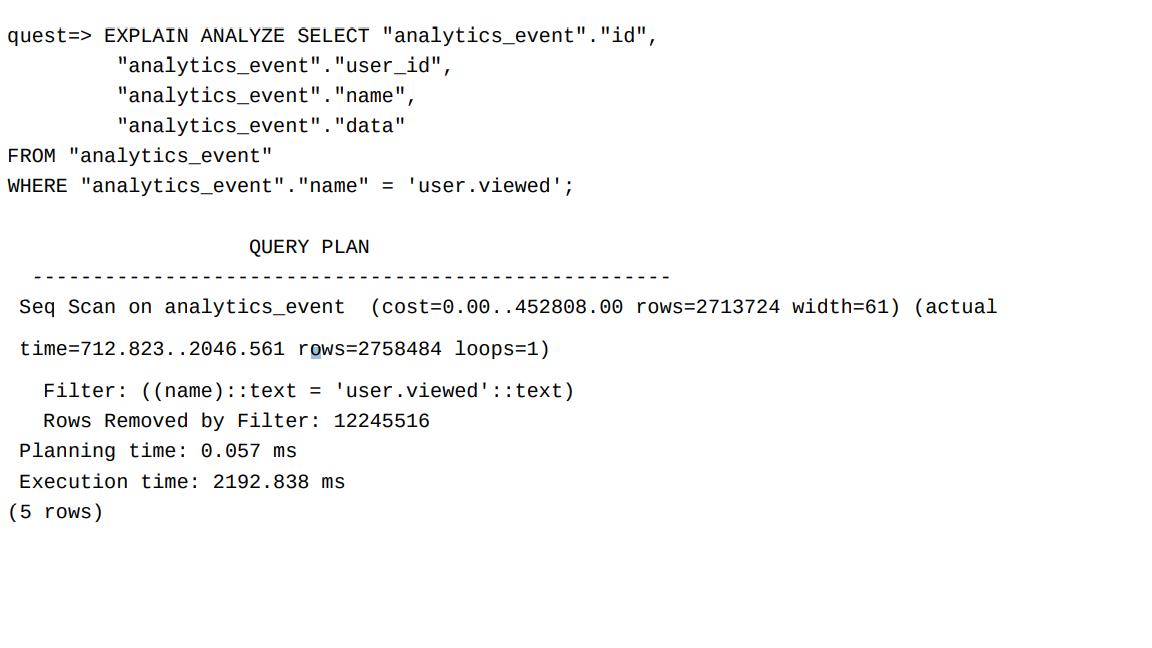
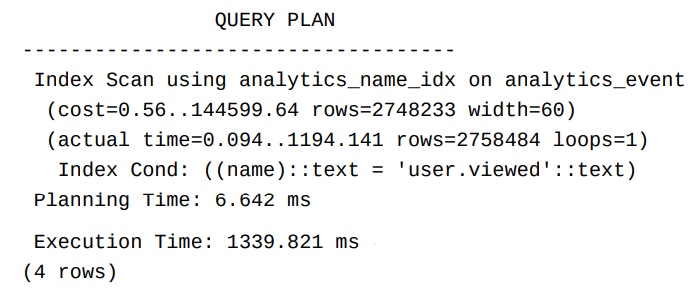
Now without an index the execution time is 2192 ms, after adding the index and executing the same query and checking its query plan we get an executing time of 1339 ms! In this case, adding an index gained us about a 40% speedup, but nothing is free as we will see.
Performance difference in WRITE operations on DB
Maintaining an Index accelerates data reading, but it comes with the trade-off of slowing down data writing. This impact is evident in operations such as inserts, updates, and deletes and this is mainly because we have to keep our indexes up to date as mentioned before which can be costly.
There are databases like Cassandra and RocksDB that use an asynchronous indexing approach using LSM(Log Structured Merge) Trees and SSTabless (Serialized String Tables). This method enhances write throughput by initially writing to an in-memory structure before "flushing" to disk. But despite the improved write speeds, this approach can result in slower read speeds.
There is one note worthy DB that may have conquered this limitation, MySQL provides an exception with MyRocks, a storage engine developed by Facebook using LSM trees, suitable for write-heavy applications.
Conclusion
Mastering database performance in Django involves a strategic approach to indexing. While the default B-tree index is fundamental, delving into advanced techniques, profiling tools, and understanding the nuances of different index types is key. Efficient indexing can significantly enhance query performance, but it's crucial to balance this with considerations for write operations and the characteristics of your database. By exploring the intricacies of indexing and staying informed about database-specific features, developers can unlock the full potential of their Django applications and ensure optimal performance for both read and write operations