How to Handle Sequences and Collections in Python?
Advanced Tips for better List and Tuple Manipulation and Sequence Handling.


In the previous article we discussed one of the most important core components of Python and that is The Data Model and the interfaces it offers us that we can leverage to make our code more robust and more readable.
Today we'll discuss an issue that is equally, if not more, important, as it's applicable to more than just Python.
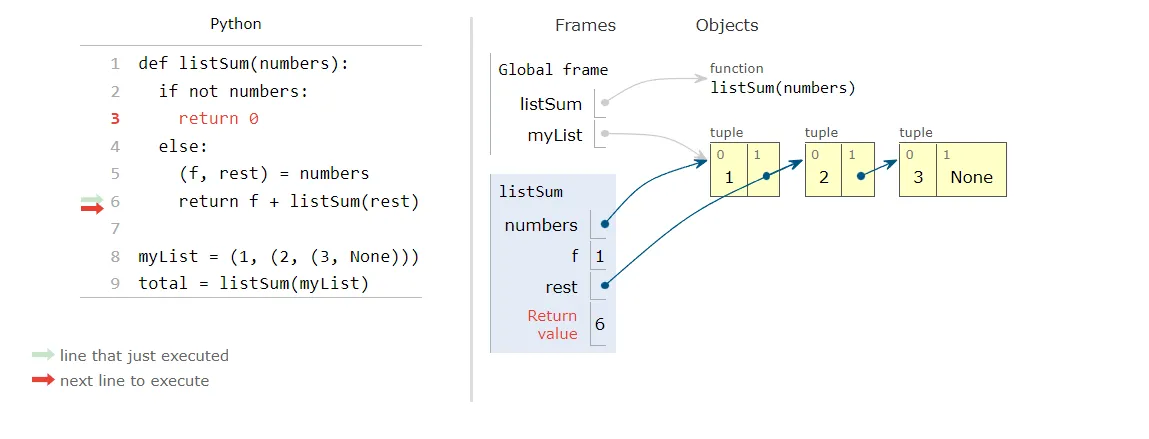
The Multiple Aspects of Sequences
Python inherited from Abstract Base Class a uniform way of handling any type of sequences from the more familiar String, Lists and Arrays to the less familiar Byte sequences, XML elements and Tuples.
Understanding the variety of sequences will spare us the reinvention of the wheel as the existing common sequence interface allows us to leverage and support any new sequence types.
In the following article we will explore
- List comprehensions
- Generator expressions
- Tuples as records
- Tuples as immutable lists
- Sequence unpacking
- Sequence pattern matching
- Slices and how to use them
- Specialized sequence types
Overview of Built-In Sequences
There are 2 types of sequences:
- The container sequences: these hold items of different types, including nested containers. Like list, tuple, and double ended queues.
- The flat sequences: these hold items of simple types. Like str and byte.
The difference is that a container sequence holds references to the objects it contains, which may be of any type, while a flat sequence stores the value of its contents in its own memory space, not as distinct Python objects.
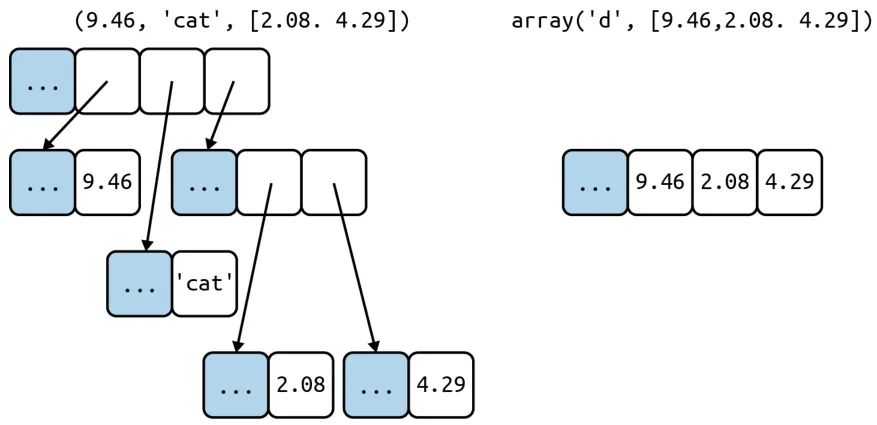
Another way to group sequences, Mutability VS Immutability:
- Mutable sequences: sequences that can change their values, for example: list, bytearray, array.array, and collections.deque.
- Immutable sequences: sequences that can not change their values, for example: tuple, str, and bytes.
List comprehensions
List Comprehensions(ListComps) and Generator expressions(GenExps) are usually misunderstood by programmers who are not used to Python.
The first deals mainly with Lists, the latter with any other type of sequences.
ListComp is very concise way to create a list from an existing list, sometimes by performing an operation on the existing items, using a simpler cleaner more compact syntax, all of this without having to deal with Python lambda.
Here’s an example using the for loop and using ListComp:
fruits = ["apple", "banana", "cherry", "kiwi", "mango"]
newlistUsingForLoop = []
newlistUsingListComp = []
# using traditional for loop
for x in fruits:
if "a" in x:
newlistUsingForLoop.append(x)
print(newlistUsingForLoop) # ['apple', 'banana', 'mango']
# using ListComp
newlistUsingListComp = [x for x in fruits if "a" in x]
print(newlistUsingListComp) # ['apple', 'banana', 'mango']
# we can notice how easily readable the list comprehension versionGenerator expressions
A generator expression(GenExps) is an expression that returns a generator object, ie. a function that contains a yield statement and returns a generator object.
They use the same syntax as listComps, but are enclosed in parentheses rather than brackets.
Here are two examples to make things clearer:
# create the generator object
squares_generator = (i * i for i in range(5))
# iterate over the generator and print the values
for i in squares_generator:
print(i)
# this will output the square of numbers from 0 to 4
colors = ['black', 'white']
sizes = ['S', 'M', 'L']
for tshirt in (f'{c} {s}' for c in colors for s in sizes):
print(tshirt)
# black S
# black M
# black L
# white S
# white M
# white LTuples as records
Tuples are usually regarded as immutable lists, but they can serve another purpose, and that is to be used as records or temporary records with no field names.
This is done as each item in the tuple holds the data for one field, and the position of the item gives its meaning, this means the number of items should be fixed and the order of items is always important.
coordinates = [(33.9425, -118.408056), (31.9425, -178.408056)]
for lat, _ in coordinates:
print(f 'cordinate latitude: {lat}')
# this will print the latitude each time ignoring the longitude value Tuples as immutable lists
Tuples are highly used in Python Standard Library as they are basically lists that do not change in size which brings clarity and performance optimization to the code.
However only the references contained in the tuple are immutable, the objects held in the references can change their values.
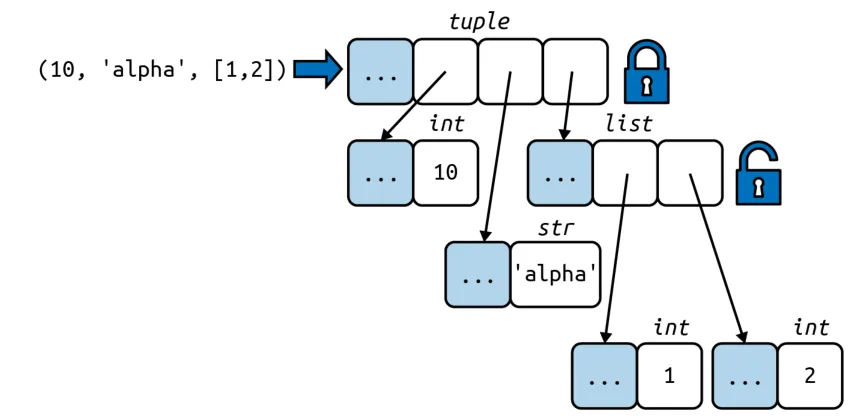
Changing the value of an item in a tuple can lead to serious bugs as tuples are hashable, it is better to use a different data structure for your specific use case.
a = (10, 'alpha', [1, 2])
b = (10, 'alpha', [1, 2])
print(a == b)
# True
b[-1].append(99)
print(a == b)
# False
print(b)
# (10, 'alpha', [1, 2, 99])Sequence Unpacking
Unpacking is an operation that consists of assigning an iterable of values to a list of variables in a single assignment statement, it avoids unnecessary and error prone use of indexes to extract elements from sequences.
coordinates = (33.9425, -118.408056)
latitude, longitude = coordinates # unpacking
print(latitude)
# 33.9425
print(longitude)
# -118.408056We can use the excess * for tuples and the excess ** for dictionaries when unpacking too.
print(green)
# apple
print(tropic)
# ['mango', 'papaya', 'pineapple']
print(red)
# cherry
# Dictionary Example
def myFish(**fish):
for name, value in fish.items():
print(f'I have {value} {name}')
fish = {
'guppies': 2,
'zebras' : 5,
'bettas': 10
}
myFish(**fish)
# I have 2 guppies
# I have 5 zebras
# I have 10 bettasSequence Pattern Matching
One of the most visible new feature in Python 3.10 is pattern matching with the match/case statement. It is very similar to the if-elif-else statement only cleaner more readable and wields the power of Destructuring.
Destructuring is a more advanced form of Unpacking, as it allows writing sequence patterns as tuples or lists or any combination of both.
Here’s a nice example I found on the GUICommits website that could simplify pattern matching with sequences. He has more examples that could help about different data structures.
baskets = [
["apple", "pear", "banana"],
["chocolate", "strawberry"],
["chocolate", "banana"],
["chocolate", "pineapple"],
["apple", "pear", "banana", "chocolate"],
]
match basket:
# Matches any 3 items
case [i1, i2, i3]:
print(f"Wow, your basket is full with: '{i1}', '{i2}' and '{i3}'")
# Matches >= 4 items
case [_, _, _, *_] as basket_items:
print(f"Wow, your basket has so many items: {len(basket_items)}")
# 2 items. First should be chocolate, second should be strawberry or banana
case ["chocolate", "strawberry" | "banana"]:
print("This is a superb combination")
# Any amount of items starting with chocolate
case ["chocolate", *_]:
print("I don't know what you plan but it looks delicious")
# If nothing matched before
case _:
print("Don't be cheap, buy something else")One thing to point out, it’s that the *_ matches any number of items without binding them to a variable. Using * extra instead of *_ would bind the items to extra as a list with 0 or more items.
Slices and how to use them
A common feature of list, tuple, str, and all Sequence Types in Python is the support of slicing operations, which are more powerful than most people realize. We will start with an example.
l = [10, 20, 30, 40, 50, 60]
l[:2] # [10, 20]
l[2:] # [30, 40, 50, 60]
l[:3] # [10, 20, 30]We slice a list like this: seq[start, stop, step], step being the number of items to skip.
To evaluate the expression seq[start:stop:step], Python calls The Special Method seq.__getitem__(slice(start, stop, step)).
s = 'bicycle'
s[::3] # 'bye'
s[::-1] # 'elcycib'
s[::-2] # 'eccb'We can assign, delete, add or multiply slices too.
l = list(range(10)) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
l[2:5] = [20, 30] # [0, 1, 20, 30, 5, 6, 7, 8, 9]
del l[5:7] # [0, 1, 20, 30, 5, 8, 9]
print(5 * 'abcd') # 'abcdabcdabcdabcdabcd'Specialized sequence types
The list type is flexible and easy to use, but depending on specific requirements, there are better options. Arrays, Memory views and Double ended queues are the prime example for that.
Arrays are a more efficient alternative when the list contains only numbers. Python arrays are as lightweight as C arrays and support all mutable sequence operations (including .pop, .insert, and .extend).
The built-in memoryview class is a shared-memory sequence type that lets you handle slices of arrays without copying bytes. Using notation similar to the array module, the memoryview.cast method lets you change the way multiple bytes are read or written as units without moving bits around.
The method memoryview.cast returns another memoryview object, always sharing the same memory.
octets = array('B', range(6)) # array of 6 bytes (typecode 'B')
m1 = memoryview(octets)
m1.tolist() # [0, 1, 2, 3, 4, 5]
m2 = m1.cast('B', [2, 3])
m2.tolist() # [[0, 1, 2], [3, 4, 5]]
m3 = m1.cast('B', [3, 2])
m3.tolist() # [[0, 1], [2, 3], [4, 5]]
m2[1,1] = 22
m3[1,1] = 33
print(octets) # array('B', [0, 1, 2, 33, 22, 5])The Deque collection is a thread-safe double-ended queue designed for fast
inserting and removing from both ends. It is also the way to go if you need to keep a list of “last seen items” or something of that nature, because a deque can be bounded , i.e. created with a fixed maximum length. If a bounded deque is full, when you add a new item, it discards an item from the opposite end.
Further reading
I tried to resume as much as possible, but I do not think that this will be enough to master the Pythonic Ways of Sequences, so here’s a list of what can help you:
- “Data Structures” chapter of the Python Cookbook, 3rd edition
- Extended Iterable Unpacking is the canonical source to read about the
new use of * extra. - The Second Chapter of the Book Fluent Python